
To borrow from an excellent analogy between the modern computer ecosystem and the US automotive industry of the 1960s, the Linux kernel runs well: when driving down the highway, you’re not sprayed in the face with oil and gasoline, and you quickly get where you want to go. However, in the face of failure, the car may end up on fire, flying off a cliff.
Rather than only taking a one-bug-at-a-time perspective, preemptive actions can stop bugs from having bad effects. With Linux written in C, it will continue to have a long tail of associated problems. Linux must be designed to take proactive steps to defend itself from its own risks. Cars have seat belts not because we want to crash, but because it is guaranteed to happen sometimes.
Even though everyone wants a safe kernel running on their computer, phone, car, or interplanetary helicopter, not everyone is in a position to do something about it. Upstream kernel developers can fix bugs, but have no control over what a downstream vendor chooses to incorporate into their products. End users get to choose their products, but don’t usually have control over what bugs are fixed nor what kernel is used (a problem in itself). Ultimately, vendors are responsible for keeping their product’s kernels safe.
What to fix?
Fix nothing?
With the preponderance of malware, botnets, and state surveillance targeting flawed software, it’s clear that ignoring all fixes is the wrong “solution.” Unfortunately this is the very common stance of vendors who see their devices as just a physical product instead of a hybrid product/service that must be regularly updated.
Fix important flaws?
Between the dereliction of doing nothing and the assumed burden of fixing everything, the traditional vendor choice has been to cherry-pick only the “important” fixes. But what constitutes “important” or even relevant? Just determining whether to implement a fix takes developer time.
The prevailing wisdom has been to choose vulnerabilities to fix based on the Mitre CVE list, presuming all important flaws (and therefore fixes) would have an associated CVE. However, given the volume of flaws and their applicability to a particular system, not all security flaws have CVEs assigned, nor are they assigned in a timely manner. Evidence shows that for Linux CVEs, more than 40% had been fixed before the CVE was even assigned, with the average delay being over three months after the fix. Some fixes went years without having their security impact recognized. On top of this, product-relevant bugs may not even classify for a CVE. Finally, upstream developers aren’t actually interested in CVE assignment; they spend their limited time actually fixing bugs.
A vendor relying on cherry-picking is all but guaranteed to miss important vulnerabilities that others are actively fixing, which is almost worse than doing nothing since it creates the illusion that security updates are being appropriately handled.
Fix everything!
So what is a vendor to do? The answer is simple, if painful: continuously update to the latest kernel release, either major or stable. Tracking major releases means gaining security improvements along with bug fixes, while stable releases are bug fixes only. For example, although modern Android phones ship with kernels that are based on major releases from almost two to four years earlier, Android vendors do now, thankfully, track stable kernel releases. So even though the features being added to newer major kernels will be missing, all the latest stable kernel fixes are present.
Performing continuous kernel updates (major or stable) understandably faces enormous resistance within an organization due to fear of regressions—will the update break the product? The answer is usually that a vendor doesn’t know, or that the update frequency is shorter than their time needed for testing. But the problem with updating is not that the kernel might cause regressions; it’s that vendors don’t have sufficient test coverage and automation to know the answer. Testing must take priority over individual fixes.
Make it happen
One question remains: how to possibly support all the work continuous updates require? As it turns out, it’s a simple resource allocation problem, and is more easily accomplished than might be imagined: downstream redundancy can be moved into greater upstream collaboration.
More engineers for fixing bugs earlier
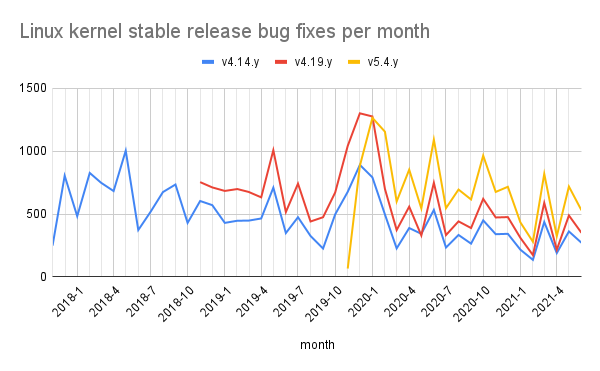
With vendors using old kernels and backporting existing fixes, their engineering resources are doing redundant work. For example, instead of 10 companies each assigning one engineer to backport the same fix independently, those developer hours could be shifted to upstream work where 10 separate bugs could be fixed for everyone in the Linux ecosystem. This would help address the growing backlog of bugs. Looking at just one source of potential kernel security flaws, the syzkaller dashboard shows the number of open bugs is currently approaching 900 and growing by about 100 a year, even with about 400 a year being fixed.
More engineers for code review
Beyond just squashing bugs after the fact, more focus on upstream code review will help stem the tide of their introduction in the first place, with benefits extending beyond just the immediate bugs caught. Capable code review bandwidth is a limited resource. Without enough people dedicated to upstream code review and subsystem maintenance tasks, the entire kernel development process bottlenecks.
Long-term Linux robustness depends on developers, but especially on effective kernel maintainers. Although there is effort in the industry to train new developers, this has been traditionally justified only by the “feature driven” jobs they can get. But focusing only on product timelines ultimately leads Linux into the Tragedy of the Commons. Expanding the number of maintainers can avoid it. Luckily the “pipeline” for new maintainers is straightforward.
Maintainers are built not only from their depth of knowledge of a subsystem’s technology, but also from their experience with mentorship of other developers and code review. Training new reviewers must become the norm, motivated by making upstream review part of the job. Today’s reviewers become tomorrow’s maintainers. If each major kernel subsystem gained four more dedicated maintainers, we could double productivity.
More engineers for testing and infrastructure
Additionally, instead of testing kernels after they’re released, it’s more effective to test during development. When tests are performed against unreleased kernel versions (e.g. linux-next) and reported upstream, developers get immediate feedback about bugs. Fixes can be developed before a flaw is ever actually released; it’s always easier to fix a bug earlier than later.
This “upstream first” approach to product kernel development and testing is extremely efficient. Google has been successfully doing this with Chrome OS and Android for a while now, and is hardly alone in the industry. It means feature development happens against the latest kernel, and devices are similarly tested as close as possible to the latest upstream kernels, all avoiding duplicated “in-house” effort.
More engineers for security and toolchain development
Besides dealing reactively to individual bugs and existing maintenance needs, there is also the need to proactively eliminate entire classes of flaws, so developers cannot introduce these types of bugs ever again. Why fix the same kind of security vulnerability 10 times a year when we can stop it from ever appearing again?
Over the last few years, various fragile language features and kernel APIs have been eliminated or replaced (e.g. VLAs, switch fallthrough, addr_limit). However, there is still plenty more work to be done. One of the most time-consuming aspects has been the refactoring involved in making these usually invasive and context-sensitive changes across Linux’s 25 million lines of code.
Beyond kernel code itself, the compiler and toolchain also need to grow more defensive features (e.g. variable zeroing, CFI, sanitizers). With the toolchain technically “outside” the kernel, its development effort is often inappropriately overlooked and underinvested. Code safety burdens need to be shifted as much as possible to the toolchain, freeing humans to work in other areas. On the most progressive front, we must make sure Linux can be written in memory-safe languages like Rust.
Don’t wait another minute
If you’re not using the latest kernel, you don’t have the most recently added security defenses (including bug fixes). In the face of newly discovered flaws, this leaves systems less secure than they could have been. Even when mediated by careful system design, proper threat modeling, and other standard security practices, the magnitude of risk grows quickly over time, leaving vendors to do the calculus of determining how old a kernel they can tolerate exposing users to. Unless the answer is “just abandon our users,” engineering resources must be focused upstream on closing the gap by continuously deploying the latest kernel release.
Based on our most conservative estimates, the Linux kernel and its toolchains are currently underinvested by at least 100 engineers, so it’s up to everyone to bring their developer talent together upstream. This is the only solution that will ensure a balance of security at reasonable long-term cost.


![]()